
В чём проблема?
Большинство инструментов тестирования производительности, включая JMeter, работает на уровне протокола HTTP, то есть они формируют HTTP-запросы, отправляют их на сервер, получают ответы и анализируют их.
Рассмотрим такую ситуацию: необходимо тестировать операцию модификации какого-то сложного объекта, при этом нужно менять не все его свойства, а только небольшую их часть.
В качестве примера возьмём форму редактирования баг-репорта в баг-трекере Mantis. Запишем рекордером сценарий, в котором выполняется логин, открывается какой-нибудь баг-репорт, выполняется переход в режим редактирования, меняется некоторое свойство и форма сохраняется. Ну и внесём сразу небольшое изменение, поместим логин внутрь блока, который исполняется только один раз:
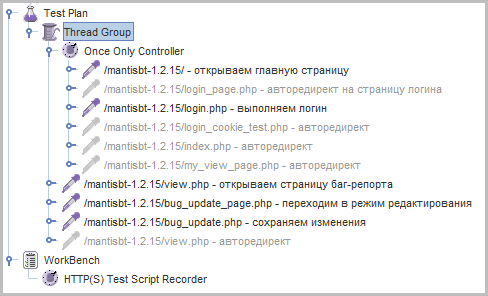
Запрос, который выполняет сохранение формы, имеет почти два десятка параметров:
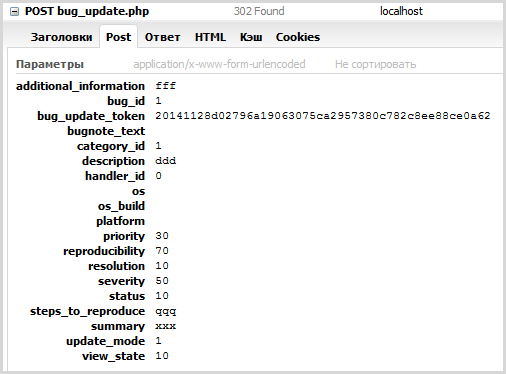
(Скриншот запроса сделан в Firebug, потому что там лучше видно параметры)
В этом случае мы должны сделать следующее:
- выполнить запрос, который загружает сложный объект
- прочитать все его свойства во временные переменные
- заполнить параметры следующего запроса значениями прочитанных переменных, изменив часть значений параметров или добавив несколько новых
Сложность представляют второй и третий шаги.
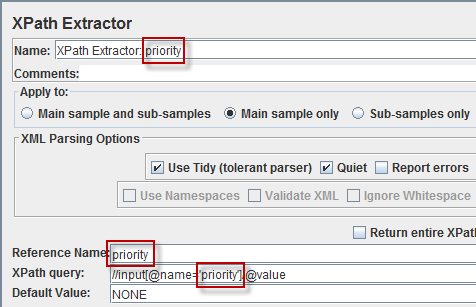
Чтобы прочитать какое-то одно свойство во временную переменную, нужно добавить в запрос так называемый экстрактор (JMeter поддерживает возможность извлечения данных при помощи XPath-запросов, CSS-селекторов и регулярных выражений).
А если надо прочитать несколько десятков свойств? Делать несколько десятков экстракторов? Хм…
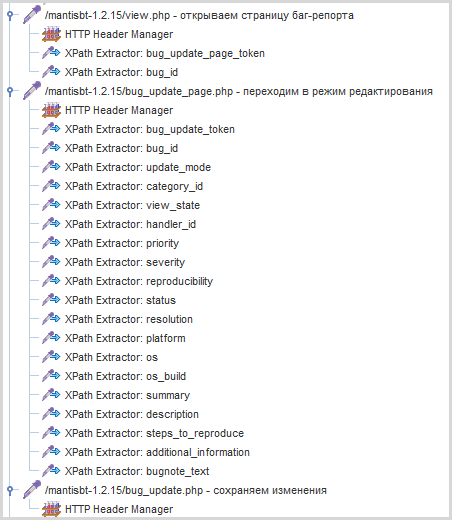
При этом все они будут выглядеть единообразно, извлекая значения полей по имени из одной и той же формы. Клонирование экстракторов – масса ручной рутинной работы.
Подстановка значений параметров чуть проще, надо записать рекордером запрос, а потом вручную (потому что в JMeter нет функции автоматической корреляции) поменять конкректные значения на переменные. Но делать эти замены – достаточно объёмный труд.
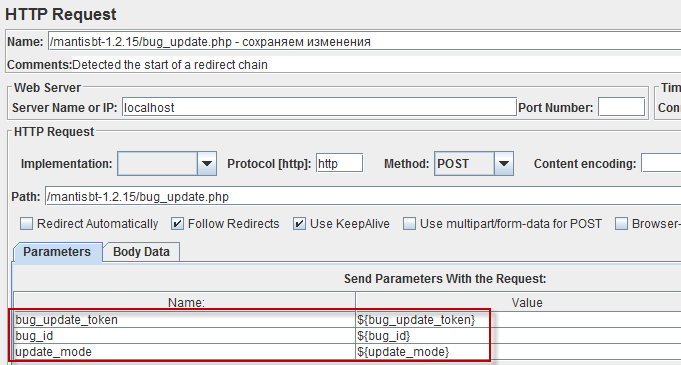
Не верите, что это реальная проблема? Думаете – два десятка подстановок, какая ерунда!
Действительно, два десятка это ерунда. Однако такая ситуация нередко встречается при тестировании систем документооборота. Каждое действие с объектом-документом меняет только часть свойств (меняется статус, ответственный, добавляется какая-то новая информация), и при этом в запросе передаются абсолютно все свойства документа, а не только те, которые меняются.
Например, в одном из проектов, которые я недавно выполнял, передавалось более шестисот (!) параметров, которые нужно было “пробрасывать” из одного запроса в другой.
И вот тут уже проблема становится по настроящему острой.
Идея решения
К счастью, JMeter позволяет писать сложные экстракторы и препроцессоры запросов на скриптовых языках программирования, и мы воспользуемся этим, чтобы справиться с описанной проблемой более эффективным способом.
Извлечение значений полей из формы
Для извлечения значений мы напишем скрипт на языке BeanShell. На вход он будет получать список имён полей, они же будут выступать в роли имён создаваемых временных переменных.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import org.apache.jorphan.util.JOrphanUtils;
import org.apache.jorphan.util.JMeterError;
import org.apache.jmeter.util.XPathUtil;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
List toExtract = new ArrayList();
for (int i = 0; i < bsh.args.length; i++) {
toExtract.add(bsh.args[i]);
}
String respData = prev.getResponseDataAsString();
byte[] utf8data = respData.getBytes("UTF-8");
ByteArrayInputStream in = new ByteArrayInputStream(utf8data);
boolean isXML = JOrphanUtils.isXML(utf8data);
Document doc = XPathUtil.makeDocument(in,false,false,false,true/*tolerant*/,true,false,false,isXML,false);
NodeList xpathRes = XPathUtil.selectNodeList(doc, "//input | //textarea");
int size = xpathRes.getLength();
for (int i = 0; i < size; i++) {
Node node = xpathRes.item(i);
String name = node.getAttribute("name");
if (toExtract.contains(name)) {
if (node.getNodeName().equals("textarea")) {
vars.put(name, node.getFirstChild().getNodeValue());
} else {
vars.put(name, node.getAttribute("value"));
}
}
}
(Это сокращённый вариант скрипта, ссылку на более полную версию вы найдёте в конце заметки)
Подробно по строкам, что здесь происходит:
1-6: Импортируем классы, которые будут использоваться в скрипте. Самым важным тут является класс XPathUtil. Мы будем выполнять XPath-запросы именно через этот вспомогательный класс, входящий в дистрибутив JMeter, потому что он имеет замечательную встроенную дополнительную возможность корректировки невалидных страниц с помощью библиотеки Tidy.
8-11: Параметры передаются в скрипт в виде массива, но это неудобно, поэтому преобразуем массив в список.
13-14: Получаем текст ответа на запрос, из которого мы и собираемся извлекать нужную информацию.
15-17: Пропускаем этот текст через XML-парсер (а также корректор Tidy) и получаем объект типа Document, к которому можно применять XPath-запросы.
18: Выполняем XPath-запрос “//input | //textarea”, который возвращает полный список полей типа input и textarea, которые найдены в документе.
19-30: В цикле проходим по всем найденным полям и проверяем их имена – если имя присутствует в списке, который был построен ранее (см. строки 8-11), значит это поле надо извлекать, поэтому берём его значение и помещаем в переменную, которая имеет такое же имя.
Ну а теперь надо прикрутить этот скрипт к нашему сценарию. Лучше всего сохранить его в файл, например, extract_parameters.bsh, и добавить к запросу BeanShell PostProcessor:
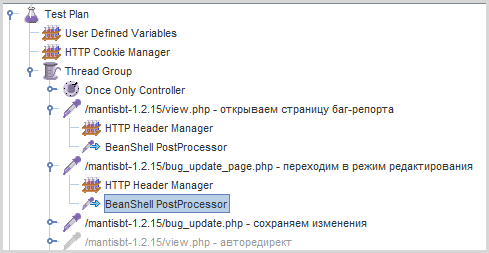
который будет выполнять этот скрипт из внешнего файла, передавая туда имена полей, которые нужно извлечь:
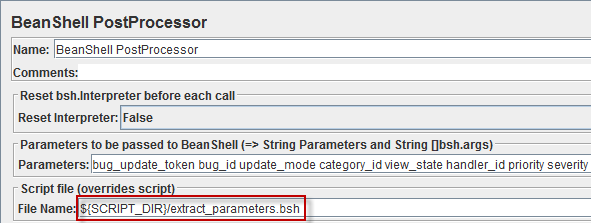
(Переменная SCRIPT_DIR установлена в самом начале сценария в элементе User Defined Variables, она указывает на директорию, в которой у меня хранятся универсальные скрипты, которые я использую в разных сценариях).
Вот и всё, теперь все переменные извлекаются при помощи одного универсального постпроцессора, который заменяет десятки или даже сотни отдельных экстракторов.
На самом деле, приведённый выше скрипт слишком прост для реальной жизни. Я обычно использую более полную версию, которая содержит некоторые дополнительные проверки, а также умеет справляться с элементами типа select (выпадающими списками), её можно найти в архиве, ссылка на который приведена в конце заметки.
Но и этого может оказаться недостаточно. Если у вас документ содержит несколько форм и в них встречаются поля с одинаковыми именами – вам нужно будет модифицировать скрипт так, чтобы выполнять более точный запрос. Если у вас есть поля, принимающие много значений (например, группа чекбоксов с одинаковыми именами) – вам опять таки придётся модифицировать этот скрипт. Это остаётся вам в качестве упражнения для самостоятельной работы.
Заполнение параметров запроса
После всего того, что происходило выше, заполнение параметров запроса – это уже совсем просто, скрипт вот такой:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import org.apache.jmeter.config.Arguments;
import org.apache.jmeter.config.Argument;
List toFill = new ArrayList();
for (int i = 0; i < bsh.args.length; i++) {
toFill.add(bsh.args[i]);
}
Arguments requestParams = sampler.getArguments();
int size = requestParams.getArgumentCount();
for (int i = 0; i < size; i++) {
Argument p = requestParams.getArgument(i);
String name = p.getName();
if (toFill.contains(name)) {
p.setValue(vars.get(name));
}
}
Его надо добавлять как препроцессор к запросу, параметры которого нужно заполнить.
Пример
Пример сценария и скрипты, которые обсуждались в заметке.
В этом сценарии извлекается информация о баг-репорте, после чего у него случайным образом выставляется новое значение для полей “severity” и “priority”, а значения остальных полей “пробрасываются” из предыдущего запроса.